
はじめに
我が家には、可愛いふわふわのイルカたち、ルイくんルカちゃんがいます。
彼らとTwitterでもお話しをしてみたかったので、彼らのように「ぽよ語」を話すTwitter BotをPythonで作りました。

作ったもの
会話ができるイルカのTwitter Bot、「電子のルカちゃん」を作りました。
「電子のルカちゃん」には、以下の機能があります。
- 5分ごとにユーザから投げられたリプライを確認します。
- リプライで受け取った文に、「モザイク」という文字列があるとき、モザイクアートを生成し、リプライします。
- 「粗」く、という文字があるとき、分割数32のモザイクアートを生成します。
- 「細」かく、という文字があるとき、分割数64のモザイクアートを生成します。
- 「粗」く、あるいは、「細」かく、といった文字がないとき、分割数64のモザイクアートを生成します。
- リプライで受け取った文に、「モザイク」という文字列がないとき、その文字列に対する返答を生成し、リプライします。
- リプライで受け取った文に、「モザイク」という文字列があるとき、モザイクアートを生成し、リプライします。
- 1日に4回、タイムラインの再頻出語を確認し、その再頻出語から開始する独り言を生成し、リプライします。
- 1日に4回、タイムラインの最新ツイートを確認し、そのツイート文字列に対する返答を生成し、リプライします。
独り言生成、および、返答生成は、ほとんど先人の知恵をお借りしました。
モザイク生成のほうが、どちらかというと、アイデンティティがあるかと思います。
以下、電子のルカちゃんがモザイク生成の説明をしてくれる画像です。
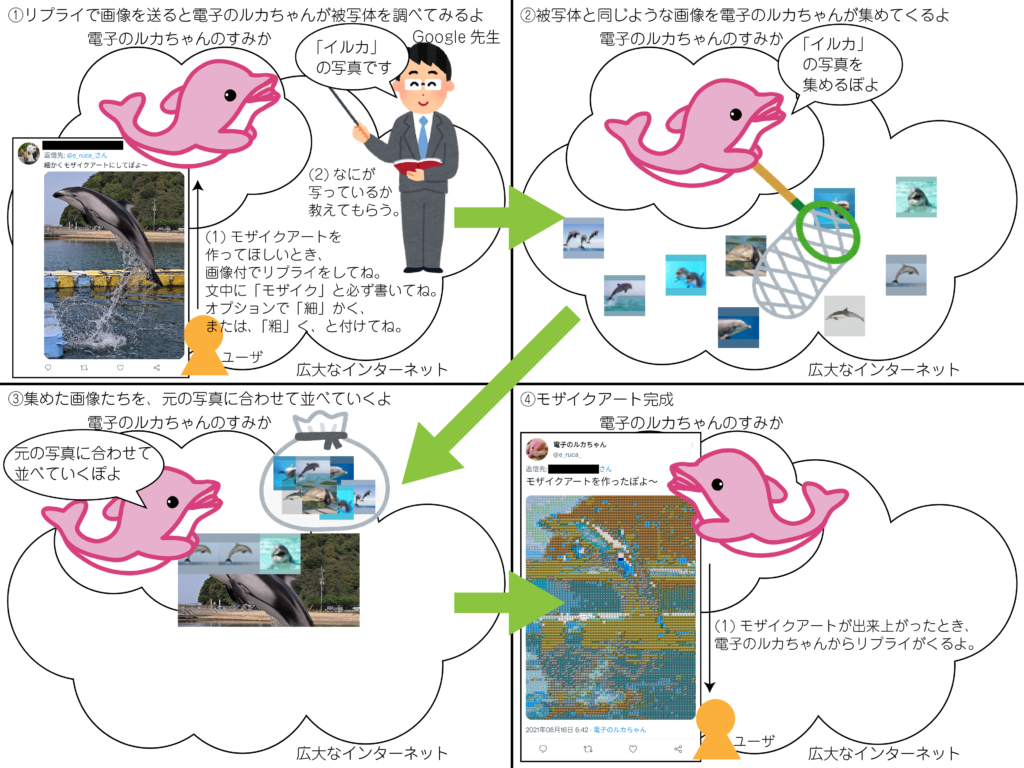
また、Twitter Botのためのアカウント作成方法は、ウェブ上に多くの情報があるので、本記事では割愛し、Pythonで作成したBot機能を説明します。
全体像
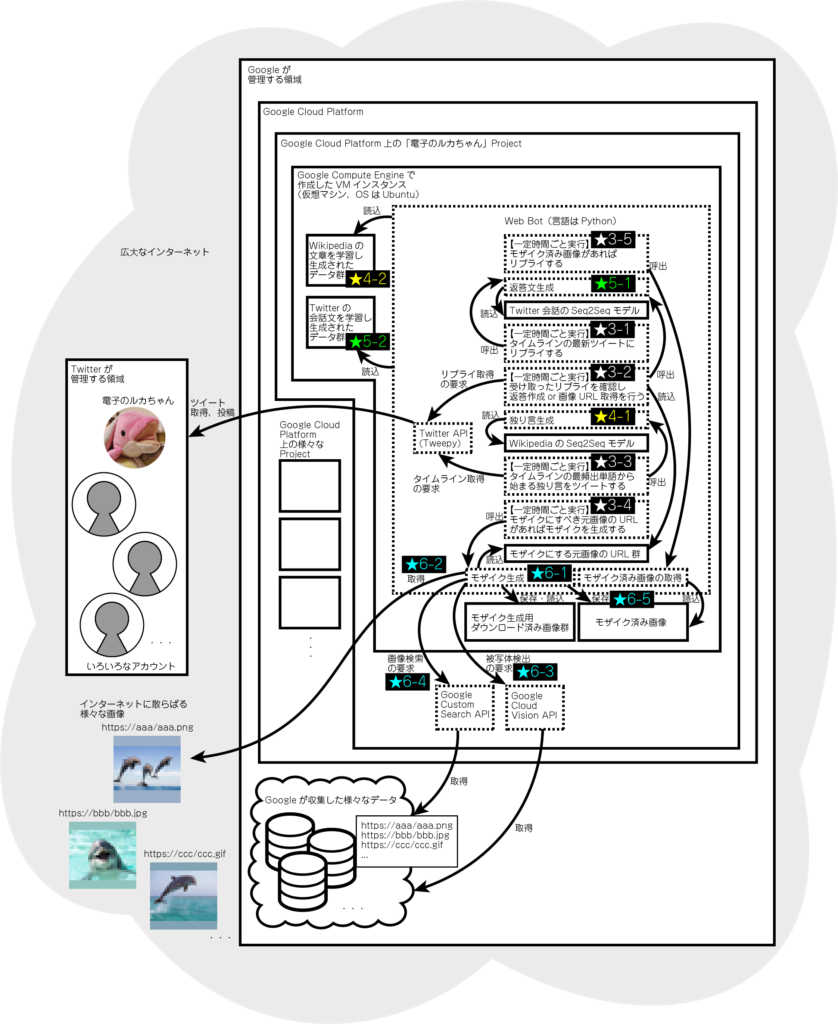
以下、5関数に対し、一定時間ごと実行するスケジュールを設定しています。
- 「タイムラインの最新ツイートにリプライする」関数(★3-1)
- 「受け取ったリプライを確認し、返答作成or画像URL取得を行う」関数(★3-2)
- 「タイムラインの再頻出単語から始まる独り言をツイートする」関数(★3-3)
- 「モザイクにすべき元画像のURLがあればモザイクを作成する」関数(★3-4)
- 「モザイク済み画像があればリプライする」関数(★3-5)
★3-2とは別に、★3-4および★3-5について、それぞれスケジュールを設定しています。
その理由は、★3-2の頻度より、★3-4でモザイク作成にかかる時間が長くなる場合があるからです。
そのため、★3-2では、モザイクにすべき画像URLを取得してストックするのみで、★3-4では、URLのストックを確認して、あればモザイクを作成します。
また、★3-4では、作成したモザイクをストックしていき、★3-5で、モザイクのストックを確認して、あればリプライします。
def twitter_bot():
# 中略
# 一定時間ごとにリプライを取得し返答する
schedule.every(CHECK_REPLY_INTERVAL_MIN).minutes.do(check_reply)
# 一定時間ごとにモザイクアートにするべき画像があるか確認する
schedule.every(CHECK_SRC_IMG_INTERVAL_MIN).minutes.do(check_src_img_urls)
# 一定時間ごとにモザイクアートになった画像があるか確認する
schedule.every(CHECK_GENERATED_IMG_INTERVAL_MIN).minutes.do(check_generated_img)
# 毎日決まった時間に独りごとを言う
for h_t in HITORIGOTO_TIME:
schedule.every().day.at(h_t).do(hitorigoto)
# 毎日決まった時間にタイムラインを確認し
# タイムラインの最新ツイート(フォローしている人の独りごと)にリプライする
for c_tl_time in CHECK_TIMELINE_TIME:
# 毎日決まった時間にタイムラインを確認してリプライする
schedule.every().day.at(c_tl_time).do(check_timeline)
error_num = 0
while True:
try:
schedule.run_pending()
time.sleep(1)
except Exception as e:
error_num += 1
logging.info('error:%d %s', error_num, e)
pass
独り言生成
以下を参考に、「独り言生成」機能を作りました。
Seq2Seqを利用した文章生成(訓練にWikipediaデータを使用) −その1 出力文の再帰入力
「独り言生成」機能(全体像★4-1)は、実行に際し、最初に一度だけ、「Wikipediaの文章を学習し生成されたデータ群」(全体像★4-2、事前に学習で生成される)をロードして、「WikipediaのSeq2Seqモデル」を用意します。
この「WikipediaのSeq2Seqモデル」を使って独り言を生成します。
def twitter_bot():
vec_dim = 400
n_hidden = int(vec_dim*1.5 ) #隠れ層の次元
args = sys.argv
#args[1] = 'param_003' # jupyter上で実行するとき用
#データロード wiki
word_indices_wiki, indices_word_wiki, words_wiki, maxlen_e_wiki, maxlen_d_wiki, freq_indices_wiki = load_data('../wikipedia')
#入出力次元 wiki
input_dim_wiki = len(words_wiki)
output_dim_wiki = math.ceil(len(words_wiki) / 8)
#モデル初期化 wiki
model_wiki, encoder_model_wiki, decoder_model_wiki = initialize_models('../wikipedia', maxlen_e_wiki, maxlen_d_wiki,
vec_dim, input_dim_wiki, output_dim_wiki, n_hidden)
#データロード 会話
word_indices_conv, indices_word_conv, words_conv, maxlen_e_conv, maxlen_d_conv, freq_indices_conv = load_data('../conversation')
#入出力次元 会話
input_dim_conv = len(words_conv)
output_dim_conv = math.ceil(len(words_conv) / 8)
#モデル初期化 会話
model_conv, encoder_model_conv, decoder_model_conv = initialize_models('../conversation', maxlen_e_conv, maxlen_d_conv,
vec_dim, input_dim_conv, output_dim_conv, n_hidden)
last_replied_id = 0
last_replied_with_mosaic_id = 0
src_img_urls = []
src_img_divisions = []
src_img_status_ids = []
with open(LAST_REPLIED_ID_TXT, 'r') as f:
last_replied_id = int(f.read())
with open(LAST_REPLIED_WITH_MOSAIC_ID_TXT, 'r') as f:
last_replied_with_mosaic_id = int(f.read())
# timelineから、最頻出語を得る
def get_hotword(until_gmt):
# Use Juman++ in subprocess mode
jumanpp = Jumanpp()
since_gmt = until_gmt + datetime.timedelta(hours=HOTWORD_HOUR)
w = []
for status in tweepy_api.home_timeline(since=since_gmt, until=until_gmt):
# 自分のツイートは除外する
if (status.user.screen_name != MY_SCREEN_NAME):
txt = status.text
txt = txt.replace('RT', '')
txt = txt.replace('#', '')
txt = txt.replace(' ', '')
txt = re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+', '', txt)
txt = re.sub(r'@\w+:\s', '', txt)
txt = re.sub(r'@\w+\s', '', txt)
for t in txt.split('\n'):
t = t.strip()
if t != '':
result = jumanpp.analysis(t)
for mrph in result.mrph_list():
if mrph.hinsi == '名詞':
is_exist_w = False
for _w in w:
if _w['w'] == mrph.midasi:
_w['n'] = _w['n'] + 1
is_exist_w = True
break
if not is_exist_w:
w.append({'w': mrph.midasi, 'n': 1})
max_n = 0
for _w in w:
if max_n < _w['n']:
max_n = _w['n']
max_w = ''
for i in range((max_n + 1), 0, -1):
for _w in w:
if _w['n'] == i:
is_match = False
for i_w in IGNORE_WORDS:
if re.match(i_w, _w['w']) != None:
is_match = True
break
if not is_match:
max_w = _w['w']
break
if max_w != '':
break
return max_w
# タイムラインの最頻出語から始まるひとりごとをツイートする
def hitorigoto():
#nonlocal n_hidden, word_indices_wiki, indices_word_wiki, words_wiki, maxlen_e_wiki, maxlen_d_wiki, freq_indices_wiki, input_dim_wiki, output_dim_wiki, model_wiki, encoder_model_wiki, decoder_model_wiki
now = datetime.datetime.now()
until_gmt = now.astimezone(timezone('GMT'))
hotword = get_hotword(until_gmt)
#--------------------------------------------------------------*
# 入力文の品詞分解とインデックス化 *
#--------------------------------------------------------------*
e_input_wiki = encode_request(hotword, maxlen_e_wiki, word_indices_wiki, words_wiki, encoder_model_wiki)
#--------------------------------------------------------------*
# 応答文組み立て *
#--------------------------------------------------------------*
decoded_sentence_wiki = generate_response_wiki(e_input_wiki, n_hidden, maxlen_d_wiki, output_dim_wiki, word_indices_wiki,
freq_indices_wiki, indices_word_wiki, encoder_model_wiki, decoder_model_wiki)
poyoed_sentence_wiki = to_poyo(decoded_sentence_wiki)
poyoed_sentence_wiki = poyoed_sentence_wiki.replace('UNK', 'アレ')
poyoed_sentence_wiki = poyoed_sentence_wiki.strip()
if is_start_meisi(poyoed_sentence_wiki):
tweet = poyoed_sentence_wiki
else:
tweet = cns_input.strip() + poyoed_sentence_wiki
try:
tweepy_api.update_status(status=tweet)
logging.info('ツイートしました:%s', tweet)
except tweepy.TweepError as e:
logging.info('tweet error')
返答生成
以下を参考に、「返答生成」機能を作りました。
Twitterデータを用いたチャットボットの訓練 -その2 処理性能とメモリ使用量改善
機械学習/ディープラーニングにおけるバッチサイズ、イテレーション数、エポック数の決め方
「返答生成」機能(全体像★5-1)は、実行に際し、最初に一度だけ、「Twitterの会話文を学習し生成されたデータ群」(全体像★5-2、事前に学習で生成される)をロードして、「Twitter会話のSeq2Seqモデル」を用意します。
この「Twitter会話のSeq2Seqモデル」を使って返答を生成します。
def twitter_bot():
vec_dim = 400
n_hidden = int(vec_dim*1.5 ) #隠れ層の次元
args = sys.argv
#args[1] = 'param_003' # jupyter上で実行するとき用
#データロード wiki
word_indices_wiki, indices_word_wiki, words_wiki, maxlen_e_wiki, maxlen_d_wiki, freq_indices_wiki = load_data('../wikipedia')
#入出力次元 wiki
input_dim_wiki = len(words_wiki)
output_dim_wiki = math.ceil(len(words_wiki) / 8)
#モデル初期化 wiki
model_wiki, encoder_model_wiki, decoder_model_wiki = initialize_models('../wikipedia', maxlen_e_wiki, maxlen_d_wiki,
vec_dim, input_dim_wiki, output_dim_wiki, n_hidden)
#データロード 会話
word_indices_conv, indices_word_conv, words_conv, maxlen_e_conv, maxlen_d_conv, freq_indices_conv = load_data('../conversation')
#入出力次元 会話
input_dim_conv = len(words_conv)
output_dim_conv = math.ceil(len(words_conv) / 8)
#モデル初期化 会話
model_conv, encoder_model_conv, decoder_model_conv = initialize_models('../conversation', maxlen_e_conv, maxlen_d_conv,
vec_dim, input_dim_conv, output_dim_conv, n_hidden)
last_replied_id = 0
last_replied_with_mosaic_id = 0
src_img_urls = []
src_img_divisions = []
src_img_status_ids = []
with open(LAST_REPLIED_ID_TXT, 'r') as f:
last_replied_id = int(f.read())
with open(LAST_REPLIED_WITH_MOSAIC_ID_TXT, 'r') as f:
last_replied_with_mosaic_id = int(f.read())
# 中略
# リプライ文を作成する
def get_reply_txt(s):
#nonlocal n_hidden, word_indices_conv, indices_word_conv, words_conv, maxlen_e_conv, maxlen_d_conv, freq_indices_conv, input_dim_conv, output_dim_conv, model_conv, encoder_model_conv, decoder_model_conv
s = s.replace('RT', '')
s = s.replace('#', '')
s = s.replace(' ', '')
s = re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+', '', s)
s = re.sub(r'@\w+:\s', '', s)
s = re.sub(r'@\w+\s', '', s)
#--------------------------------------------------------------*
# 入力文の品詞分解とインデックス化 *
#--------------------------------------------------------------*
e_input_conv = encode_request(s, maxlen_e_conv, word_indices_conv, words_conv, encoder_model_conv)
#--------------------------------------------------------------*
# 応答文組み立て *
#--------------------------------------------------------------*
decoded_sentence_conv = generate_response_conv(e_input_conv, n_hidden, maxlen_d_conv, output_dim_conv, word_indices_conv,
freq_indices_conv, indices_word_conv, encoder_model_conv, decoder_model_conv)
poyoed_sentence_conv = to_poyo(decoded_sentence_conv)
poyoed_sentence_conv = poyoed_sentence_conv.replace('UNK', 'アレ')
poyoed_sentence_conv = poyoed_sentence_conv.strip()
reply = poyoed_sentence_conv
return reply
# リプライする
def reply(reply_txt, screen_name, status_id):
nonlocal last_replied_id
if last_replied_id < status_id:
last_replied_id = status_id
with open(LAST_REPLIED_ID_TXT, 'w') as f:
f.write(str(last_replied_id))
else:
logging.info('そのツイートID宛に、既にリプライした可能性があります:%d', last_replied_id)
return
tweet = "@" + screen_name + "\n" + reply_txt
try:
# リプライする
tweepy_api.update_status(status=tweet, in_reply_to_status_id=status_id)
logging.info('リプライしました:%s', tweet)
except tweepy.TweepError as e:
logging.info('tweet error')
# 中略
# 受け取ったリプライを確認し、それらにリプライする
def check_reply():
nonlocal last_replied_id, last_replied_with_mosaic_id, src_img_urls
# 画像無リプライを取得する
for mention in tweepy.Cursor(tweepy_api.mentions_timeline, since_id=last_replied_id).items():
users_mention_entities = mention.entities
users_mention_txt = mention.text
users_mention_id = mention.id
users_id = mention.user.id
users_screen_name = mention.user.screen_name
users_mention_txt = users_mention_txt.replace(('@' + MY_SCREEN_NAME), '')
users_mention_txt = users_mention_txt.replace('\n', ' ')
users_mention_txt = users_mention_txt.strip()
logging.info('%sさんのメンション:%s', users_screen_name, users_mention_txt)
if users_mention_txt.startswith(FOLLOW_ME_STR):
try:
tweepy_api.create_friendship(users_id)
reply(I_FOLLOWED_YOU_STR, users_screen_name, users_mention_id)
logging.info('フォローしました:%s', users_screen_name)
except:
logging.info('フォロー済です:%s', users_screen_name)
elif MOSAIC_STR not in users_mention_txt:
my_reply_txt = get_reply_txt(users_mention_txt)
reply(my_reply_txt, users_screen_name, users_mention_id)
# 画像付リプライを取得する
for mention in tweepy.Cursor(tweepy_api.mentions_timeline, since_id=last_replied_with_mosaic_id).items():
users_mention_entities = mention.entities
users_mention_txt = mention.text
users_mention_id = mention.id
users_id = mention.user.id
users_screen_name = mention.user.screen_name
users_mention_txt = users_mention_txt.replace(('@' + MY_SCREEN_NAME), '')
users_mention_txt = users_mention_txt.replace('\n', ' ')
users_mention_txt = users_mention_txt.strip()
logging.info('%sさんのメンション:%s', users_screen_name, users_mention_txt)
if 'media' in users_mention_entities and MOSAIC_STR in users_mention_txt:
if len(users_mention_entities['media']) == 1:
media_url = users_mention_entities['media'][0]['media_url_https']
src_img_urls.append(media_url)
src_img_status_ids.append(users_mention_id)
if COARSE_STR in users_mention_txt:
src_img_divisions.append(COARSE_MOSAIC_DIVISION)
else:
src_img_divisions.append(FINE_MOSAIC_DIVISION)
else:
reply(NOT_1_SRC_IMG, users_screen_name, users_mention_id)
# タイムラインの最新ツイートにリプライする
def check_timeline():
for status in tweepy_api.home_timeline(count=GET_LATEST_TWEETS_NUM):
# リツイートや引用リツイート、自分のツイートは除外する
if (not status.retweeted) and ("@" not in status.text) and (status.user.screen_name != MY_SCREEN_NAME):
logging.info('%sさんのツイート:%s', status.user.screen_name, status.text)
my_reply_txt = get_reply_txt(status.text)
reply(my_reply_txt, status.user.screen_name, status.id)
break
モザイク生成
以下、モザイク生成(全体像★6-1)の流れです。
- モザイクにする元画像取得(全体像★6-2)
- 元画像の被写体のワード取得(全体像★6-3)
- 被写体のワードによる画像検索(全体像★6-4)
- 元画像のタイル化および、色が似ている箇所へ③の各画像配置(全体像★6-1)
- 完成したモザイク画像の保存(全体像★6-5)
- モザイク済み画像があればリプライ(全体像★3-5)
モザイクアートの作り方は、以下をご参照ください。
def twitter_bot():
# 中略
# 画像付きリプライする
def reply_with_imgs(reply_txt, screen_name, status_id, img_paths):
nonlocal last_replied_with_mosaic_id
if last_replied_with_mosaic_id < status_id:
last_replied_with_mosaic_id = status_id
with open(LAST_REPLIED_WITH_MOSAIC_ID_TXT, 'w') as f:
f.write(str(last_replied_with_mosaic_id))
else:
logging.info('そのツイートID宛に、既にリプライした可能性があります:%d', last_replied_with_mosaic_id)
return
tweet = "@" + screen_name + "\n" + reply_txt
'''
'画像をTwitterにアップロードする
'''
media_ids = []
for img_path in img_paths:
img = tweepy_api.media_upload(img_path)
media_ids.append(img.media_id)
try:
# リプライする
tweepy_api.update_status(status=tweet, in_reply_to_status_id=status_id, media_ids=media_ids)
logging.info('リプライしました:%s %s', tweet, str(media_ids))
except tweepy.TweepError as e:
logging.info('tweet error: %s', e)
# 受け取ったリプライを確認し、それらにリプライする
def check_reply():
nonlocal last_replied_id, last_replied_with_mosaic_id, src_img_urls
# 画像無リプライを取得する
for mention in tweepy.Cursor(tweepy_api.mentions_timeline, since_id=last_replied_id).items():
users_mention_entities = mention.entities
users_mention_txt = mention.text
users_mention_id = mention.id
users_id = mention.user.id
users_screen_name = mention.user.screen_name
users_mention_txt = users_mention_txt.replace(('@' + MY_SCREEN_NAME), '')
users_mention_txt = users_mention_txt.replace('\n', ' ')
users_mention_txt = users_mention_txt.strip()
logging.info('%sさんのメンション:%s', users_screen_name, users_mention_txt)
if users_mention_txt.startswith(FOLLOW_ME_STR):
try:
tweepy_api.create_friendship(users_id)
reply(I_FOLLOWED_YOU_STR, users_screen_name, users_mention_id)
logging.info('フォローしました:%s', users_screen_name)
except:
logging.info('フォロー済です:%s', users_screen_name)
elif MOSAIC_STR not in users_mention_txt:
my_reply_txt = get_reply_txt(users_mention_txt)
reply(my_reply_txt, users_screen_name, users_mention_id)
# 画像付リプライを取得する
for mention in tweepy.Cursor(tweepy_api.mentions_timeline, since_id=last_replied_with_mosaic_id).items():
users_mention_entities = mention.entities
users_mention_txt = mention.text
users_mention_id = mention.id
users_id = mention.user.id
users_screen_name = mention.user.screen_name
users_mention_txt = users_mention_txt.replace(('@' + MY_SCREEN_NAME), '')
users_mention_txt = users_mention_txt.replace('\n', ' ')
users_mention_txt = users_mention_txt.strip()
logging.info('%sさんのメンション:%s', users_screen_name, users_mention_txt)
if 'media' in users_mention_entities and MOSAIC_STR in users_mention_txt:
if len(users_mention_entities['media']) == 1:
media_url = users_mention_entities['media'][0]['media_url_https']
src_img_urls.append(media_url)
src_img_status_ids.append(users_mention_id)
if COARSE_STR in users_mention_txt:
src_img_divisions.append(COARSE_MOSAIC_DIVISION)
else:
src_img_divisions.append(FINE_MOSAIC_DIVISION)
else:
reply(NOT_1_SRC_IMG, users_screen_name, users_mention_id)
# 中略
# モザイクアートにするべき画像があるか確認し、あればモザイクアートを作成する
def check_src_img_urls():
nonlocal src_img_urls, src_img_divisions, src_img_status_ids
files = glob.glob(GENERATED_IN_MOSAIC + '/*')
if len(files) == 0: # GENERATED内に画像ないとき処理中
return
if REPLIED_STR not in files[0]: # reply前ならパス
return
if len(src_img_urls) > 0:
src_img_url = src_img_urls.pop(len(src_img_urls) - 1)
division = src_img_divisions.pop(len(src_img_divisions) - 1)
status_id = src_img_status_ids.pop(len(src_img_status_ids) - 1)
original_img_bytes = None
try:
r = requests.get(src_img_url, timeout=5.0)
if r.headers['content-type'] == 'image/webp':
logging.info("failed to download images.")
return None
original_img_bytes = r.content
except Exception as e:
logging.info("failed to download images. %s", e)
return None
with ThreadPoolExecutor() as executor:
feature = executor.submit(generate_mosaic_art(original_img_bytes, division, status_id))
return
# モザイクアートになった画像があるか確認し、あればリプライする
def check_generated_img():
files = glob.glob(GENERATED_IN_MOSAIC + '/*')
for f in files:
file_name = f.split('/')[-1]
if REPLIED_STR not in file_name:
reply_txt = REPLY_WITH_MOSAIC_STR
status_id = int(file_name.replace('.png', ''))
status = tweepy_api.get_status(status_id)
screen_name = status.user.screen_name
reply_with_imgs(reply_txt, screen_name, status_id, [f])
rename_path = GENERATED_IN_MOSAIC + '/' + REPLIED_STR + file_name
shutil.move(f, rename_path)
return
参考
Seq2Seqを利用した文章生成(訓練にWikipediaデータを使用) −その1 出力文の再帰入力
Twitterデータを用いたチャットボットの訓練 -その2 処理性能とメモリ使用量改善